Shortlisted Candidate — Communications Digital Officer · ETC2 · Req 35105
Michael Douma
A few minutes on…
What I’d propose for CIF.org.
Generative Engine Optimization.
Me and AI-powered new things.
March 2026
Good afternoon. I’m Michael Douma. Thanks for booting up this presentation. And thank you for shortlisting me. Here’s a few minutes on what I’d propose for CIF, on generative engine optimization, and a little bit about me and AI-powered things. — Next to slide #2
Part 1 — What I’d Propose · 3 minutes
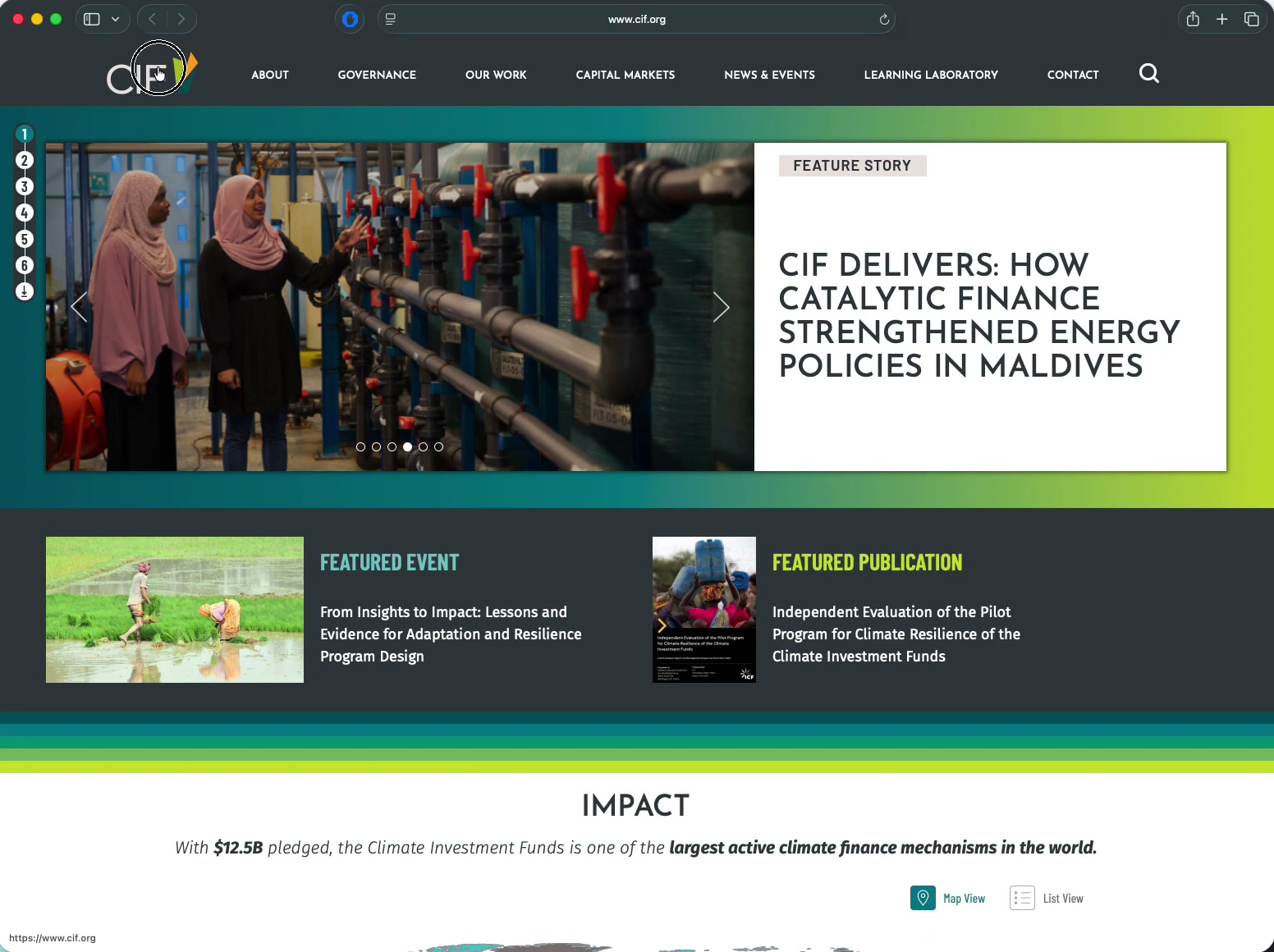
What Changes I Would Propose for CIF.org
You asked what changes I’d propose for CIF. Ideally, I’d start by learning from your users or the staff who work with them. As a workaround, I reverse-engineered your users and hypothetically interviewed them. — Next to slide #3
Part 1 — User Research · 3 minutes
I reverse-engineered 9 user personas for CIF.org
AI analysis of the site’s content architecture, tone, jargon, and navigation pathways revealed every distinct audience — from bond investors to Indigenous community leaders.
Primary
Recipient Governments
Ministry officials designing investment plans and reporting results.
Primary
MDB Staff
Specialists at World Bank, IFC, ADB, AfDB, EBRD, IDB implementing CIF projects.
Primary
Donor Governments
Treasury & development officials from 15 contributor nations.
Secondary
Institutional Investors
Pension funds & asset managers evaluating CCMM bonds.
Secondary
Private Sector
Renewable energy developers seeking concessional finance through MDBs.
Secondary
Researchers
Climate finance scholars studying CIF’s mechanisms and evidence.
Tertiary
Civil Society / NGOs
Watchdogs monitoring governance, pushing for safeguards.
Tertiary
Indigenous Peoples
IPLC leaders accessing the Dedicated Grant Mechanism.
Tertiary
Youth / Early-Career
Young professionals seeking the CIF Youth Fellowship and careers.
You seem to have around 9 overall user personas. The primaries are your recipients, other development bank staff, and donors. Then secondary audiences — investors and researchers. And a tertiary audience — I’m not sure if that’s intentional or a side benefit — civil society, Indigenous peoples, and young people. So let’s pretend to talk to them. — Next to slide #4
Persona Findings
What users like
73 Country Dashboards
- Most-praised feature across 5 personas
- Population, emissions, funding in one place
Decision Tracker
- Searchable governance database — best in class
- Valued by govts, MDBs, donors, CSOs, researchers
Knowledge Hub
- 13 publication types, multi-faceted search
- Tiered: full report → brief → article
Co-financing Data
- 1:10 ratio is CIF’s most powerful proof point
- Clear donut charts with data timestamps
Governance Transparency
- Meeting archives back to 2016
- Exceeds most multilateral fund peers
Visual Credibility
- Clean institutional aesthetic, strong brand
- DGM pages + ChangeMakers prove accessible writing works
Good news first — and again, these are synthetic personas standing in for real interviews — your users love the country dashboards. The Decision Tracker is great. And the Knowledge Hub seems impressive. — Next to slide #5
Persona Findings
What users find problematic
No audience entry points
- All 9 personas land on the same homepage
- No “For Governments” / “For Communities” routing
Showcase over utility
- Site is a brochure first, a working tool second
- Homepage helps no one do their actual job
Results are aggregate-only
- 42.7M tons CO2 — no country/program breakdown
- “87 of 173 reporting” buried in footnotes
Nav follows the org chart
- M&R Toolkits hidden under “Learning Laboratory”
- One workflow touches 5 of 7 nav sections
Misallocated real estate
- Capital Markets gets a full nav slot
- DGM (only direct grants) buried 2 levels deep
No current calls page
- Funding info scattered across news, governance, KB
- Contact page: 3 generic emails for 9 audiences
And these synthetic users had issues, though. They didn’t really know where to go from their perspective. The site presents more like a brochure and an annual report. And the overall frustration was that the question they had in mind when they showed up at the site, they didn’t quite know how to solve. — Next to slide #6
What This Means
It’s about usability and clear paths to data
The site looks good. The content is rich. The problem is structural — it’s not organized around how people actually find and use what they need.
1
Listen first
Hear from the team. What’s been tried, what worked, what didn’t, what constraints shaped the current site. Enter the history — don’t assume a blank slate.
2
Map the user journeys
Follow each persona’s actual path through the site. Where do they get lost? Where do they give up? The data is in the analytics — supplement it with the persona research.
3
Focus on the architecture
If a user can’t find what they need in three clicks, the structure isn’t working. Strip back to the information architecture and make every path to data clear and direct.
Beautiful and usable are not in tension. But usable has to come first.
As an outsider who spent some time diving in and reading between the lines on the synthetic personas — what I see is a mature site that has maybe expanded too much. And that’s perhaps why it’s hard to know where to go as a user. There’s clearly deep content and data that’s there. The approach I’d bring: hear from the team or stakeholders if that’s possible. Map what it is that people need. And then think about the architecture changes that could help people not only get what they want, but get what they didn’t know they wanted. — Next to slide #7
Part 2 — Generative Engine Optimization · 2 minutes
Making CIF.org the source AI engines quote
When someone asks ChatGPT “What are the largest multilateral climate funds?” — CIF.org should be cited. Structural gaps prevent this today.
-25%
Drop in traditional search volume by 2026 (Gartner)
+693%
Surge in AI referral traffic, 2025 holiday season (Adobe)
2–7
Sources cited per AI answer. You must be one of them.
+40%
Visibility boost from GEO techniques (Princeton/Georgia Tech, KDD 2024)
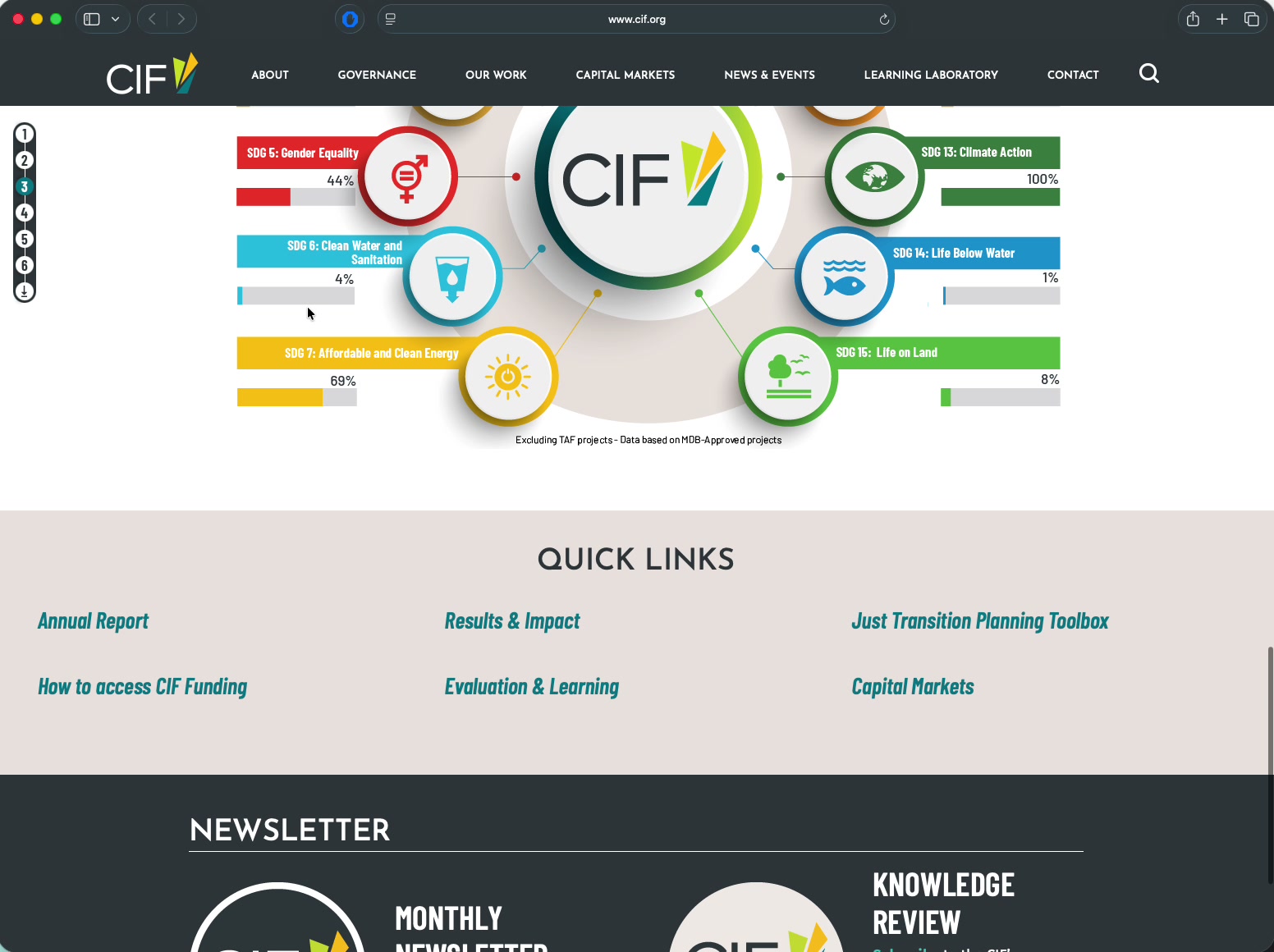
Current Quick Links — no structured data for AI crawlers
The next question you asked me about was generative engine optimization — how do you get a frontier model to cite CIF in its inferences? I think it’s great that you’re asking this question. Search engine traffic is down. AI usage is up. You’re on point here. — Next to slide #8
The Deeper Principle
How LLMs decide what’s worth quoting
Beyond metadata and schema, there’s a fundamental principle: LLMs’ attention mechanisms latch onto specific, distinctive, quotable facts. If CIF’s pages read like generic brochure copy, AI engines will skip them for a source that offers concrete claims.
What AI engines ignore
“CIF supports ambitious climate action in developing countries through its portfolio of programs.” — This is interchangeable with any fund’s about page. No attention head fires. Nothing to cite.
What AI engines quote
“CIF has deployed $12.5B across 81 countries, leveraging $73B in co-financing at a 1:10 ratio — making it the world’s largest multilateral climate finance mechanism by leverage.” — Specific. Unique. Citable.
Lead with numbers
Every program page should open with its specific stats: dollars deployed, countries reached, tons mitigated.
Make claims comparative
“Largest,” “first,” “only” — superlatives give LLMs confidence that this is the primary source. CIF has many legitimate firsts.
Front-load each page
44% of AI citations come from the first 30% of a page. The most important facts must appear in the first two paragraphs, not in a PDF.
The overall answer, as I understand it, is that you need to put content online that’s not just indexable from a keyword perspective, but that’s quote-worthy. LLMs have certain things they look for when they want to condense large amounts of content. They look for readable, findable, believable, specific facts — storable and then producible to their users. — Next to slide #9
01
GEO Action 1
Fix metadata & add structured data
CIF.org has zero JSON-LD structured data. The homepage title reads “CIF” — not “Climate Investment Funds.” AI engines can’t identify the entity.
- Fix title: “Climate Investment Funds (CIF) | Accelerating Climate Action in Developing Countries”
- Add Organization schema with founding date, World Bank relationship, mission
- Add Article/Report schema to 400+ publications with author, date, dateModified
- Add FAQPage schema answering “How does CTF work?” on every program page
- Deploy llms.txt at site root mapping key resources
Pages with 3+ schema types are ~13% more likely to be cited in AI answers.
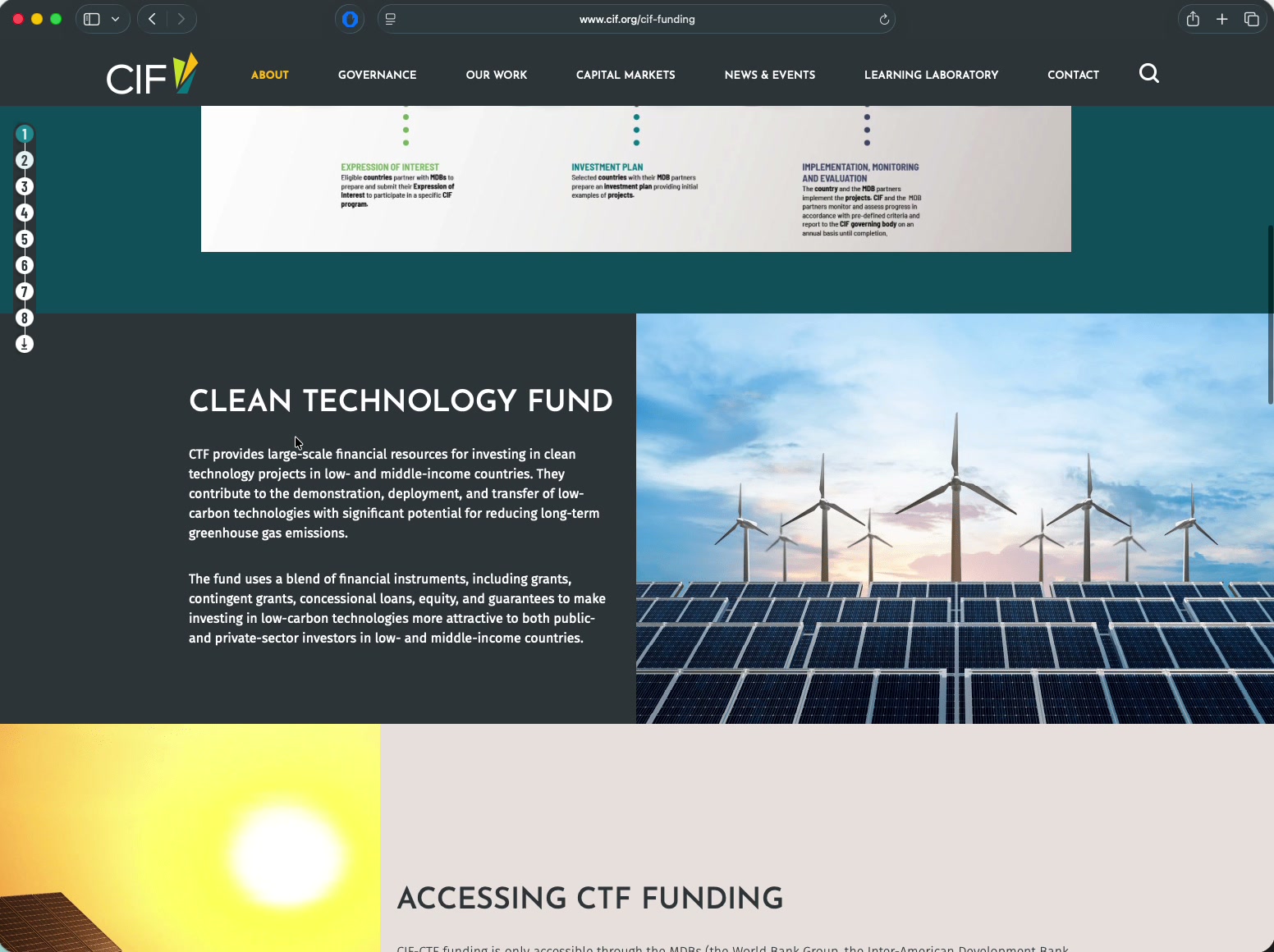
// What should exist on every page:
<script type="application/ld+json">
{ "@type": "Organization",
"name": "Climate Investment Funds",
"alternateName": "CIF",
"parentOrganization": "World Bank"
}
</script>
One level is pretty mechanical — embedding computer-readable structured data into the site. Data that, as far as I can tell, isn’t embedded right now. — Next to slide #10
02
GEO Action 2
Convert PDFs to citable HTML & build topic clusters
CIF’s most valuable content — evaluations, investment plans — is locked in PDFs. AI crawlers can’t index them.
- HTML landing pages for top 50 PDFs with executive summaries and extractable data
- Build topical authority clusters: “Climate Finance Mechanisms” pillar linking to program sub-pages
- Add 2–4 sentence “answer capsules” under every H2 heading
- Reduce navigation markup bloat — lazy-load faceted filters
Queries CIF should own
“What is the Clean Technology Fund?” · “Largest multilateral climate funds” · “How does concessional climate finance work?” · “Coal transition financing”
The next level is making more content that’s not just web pages readable and digestible. So the LLM knows what’s in a video, what’s in a document, what’s in a report. This probably involves bulk-level conversion and digestion of your documents. — Next to slide #11
03
GEO Action 3
Build cross-platform authority so AI engines trust CIF
The strongest predictor of AI citations is brand search volume (0.334 correlation), not backlinks. 90% of AI citations come from earned & owned media.
- Audit & enrich Wikipedia articles about CIF — ChatGPT’s #1 source (7.8% of citations)
- Engage on social media like Reddit climate finance discussions — top source for AI Overviews & Perplexity
- Full metadata + transcripts + chapters on all YouTube content
- Data-rich LinkedIn posts (29.4K followers) AI engines can reference
- Create a definitive “About CIF” page — single source of truth for AI extraction
- Allow AI search bots while blocking training bots in robots.txt
AI-referred visitors convert at 4.4x the rate of organic search visitors.
The opportunity
CIF has unique, authoritative, data-rich climate finance content no other source can replicate. The challenge is purely structural — making it discoverable, extractable, and citable.
And thirdly, GEO — a little bit like SEO — is bigger than your website. The engine needs to know why to cite your site. It’s kind of a brand question. Your brand presence — Wikipedia, social media sites like Reddit, YouTube — is an essential piece of why an LLM would point people to your site. — Next to slide #12
As an Outsider Looking In
Where to start
First Month
- Maintain continuity with whoever I’m replacing or augmenting
- Learn the team’s needs, workflows, and constraints
- Audit what’s in the back catalog — what can AI extract from existing PDFs, reports, and data?
First Quarter
- Map how different audiences actually use the site
- Write initial data-heavy specs for the vendor — metadata, structured data, machine-readable content
- Audit the broader ecosystem — Wikipedia, social media, other sites — for GEO impact
First Year
- A GEO/LLM-friendly site with structured, citable content
- Clearer paths to relevant information for different user types
- Cross-platform authority built with the comms team
The question is, what would I do? I don’t know yet. But the place to start is continuity with what you’re doing now, learning your frameworks and workflows. And importantly, understanding what’s in the back catalog — because I think that’s what you want search engines to share and for users to discover. The next layer, maybe in the first quarter, would be understanding how people use the site and preparing communication with your vendor — so we can get structured data into the website, because that’ll have its own timeline. And ideally, a year from now, you have improvements we all think are a good idea — a much more GEO-friendly site, and a clearer way for different users to find information. — Next to slide #13
About Me
Michael Douma
Science & Literacy
25 years in science, art, and cultural literacy. Time.gov at NIST, WebExhibits (350M views), SpicyNodes (40M users).
Games & AI Systems
A decade in games and large-scale AI. NSF-funded semantic database, 100M+ relationships, 130M AI operations. Founder experience.
Data Visualization
Deep interest in making complex data usable, browsable, and understandable for non-specialist audiences.
Climate
Personally interested in climate impacts, and the real incentives that tip the needle for reducing destruction and helping people adapt.
Why I’m Here
I want to work in climate and development. AI and data skills are my way in.
Communications Digital Officer · ETC2 · Req 35105
Let me briefly set the scene for why I’m interested in this job. My career arc has gone from science and cultural literacy, to a decade of word games empowered by large-scale AI, to data visualization. I’m personally very interested in climate — I feel like our planet is being destroyed. And I’m thinking that my AI and data skills are a foothold to start working in climate and development. This position is appealing to me. — Next to slide #14
 An NSF-Funded Project I Founded
An NSF-Funded Project I Founded
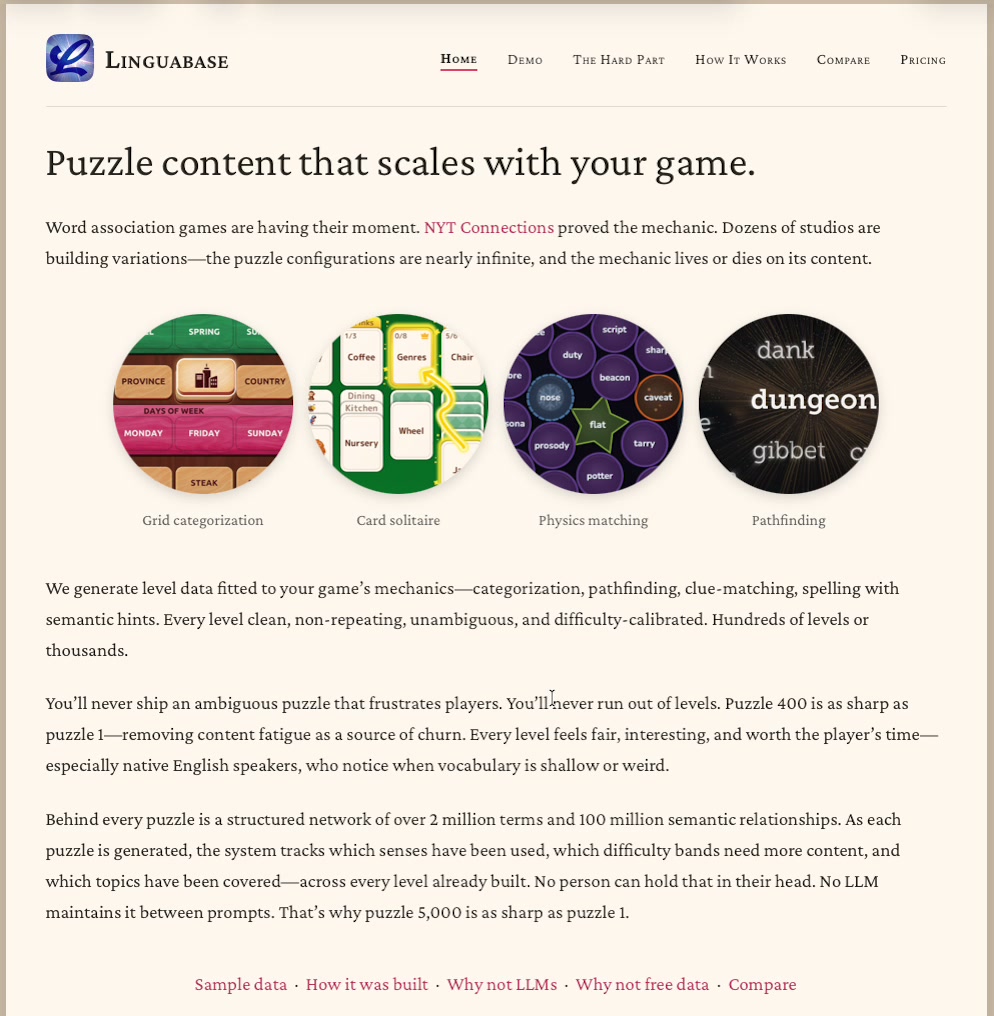
Linguabase: the world’s largest word–game data system
A structured graph of 400K words and 100M+ semantic connections, built over a decade with NSF supercomputer time, 70+ reference sources, and 130 million AI validation calls. Puzzle content for word games — clean, non-repeating, difficulty-calibrated, at any scale.
This is the anchor of the AI skills I’d bring to CIF — a decade of working at the intersection of structured data, language, and machine intelligence.
I spent a number of years working on word games, funded by the National Science Foundation. These games required a lot of data. Building out a semantic database of 100 million connections was done using over 130 million AI inferences. This is part of a finished project that has launched games. — Next to slide #15
Built in 3 Weeks
The entire website — built with agentic AI tools
Three weeks ago this site didn’t exist. Interactive games, data visualizations, a client portal — hand-coded, no frameworks, no build step. This is what’s possible now.
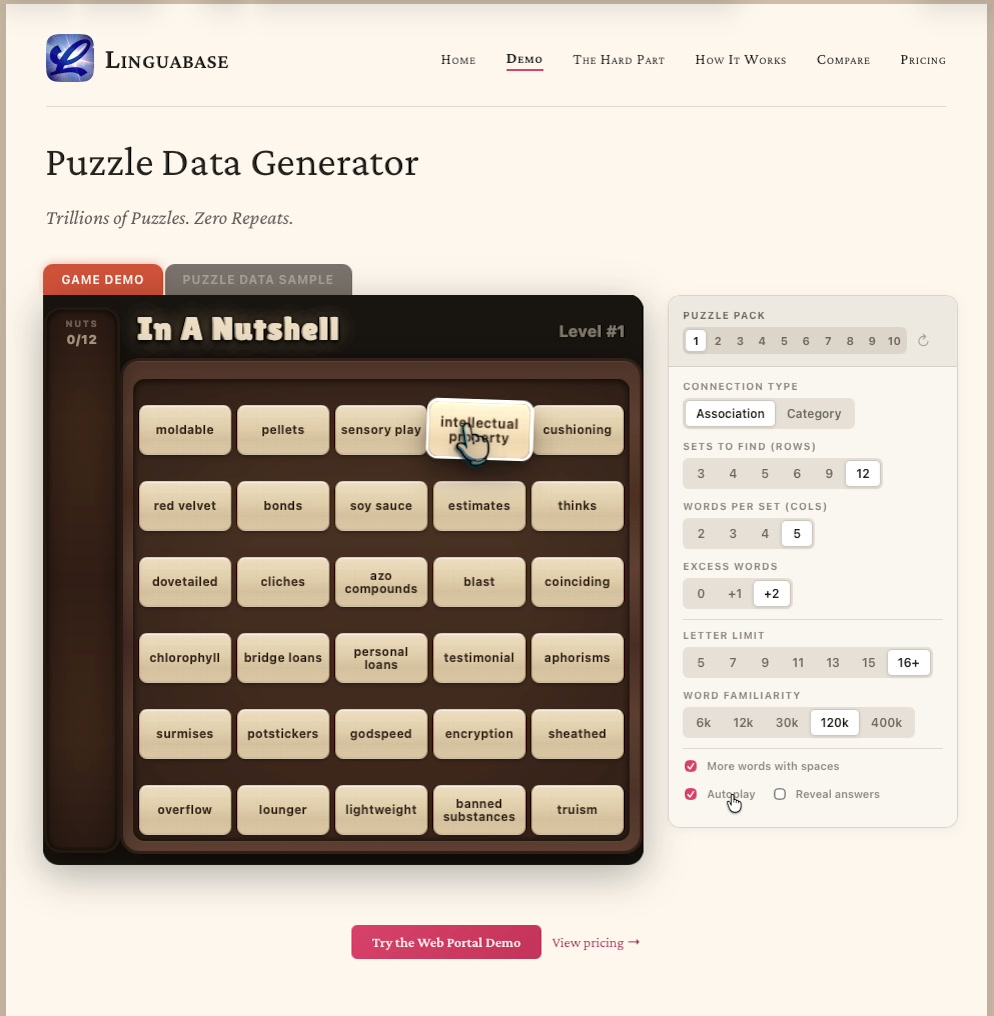
Interactive configurator

Physics-based word game
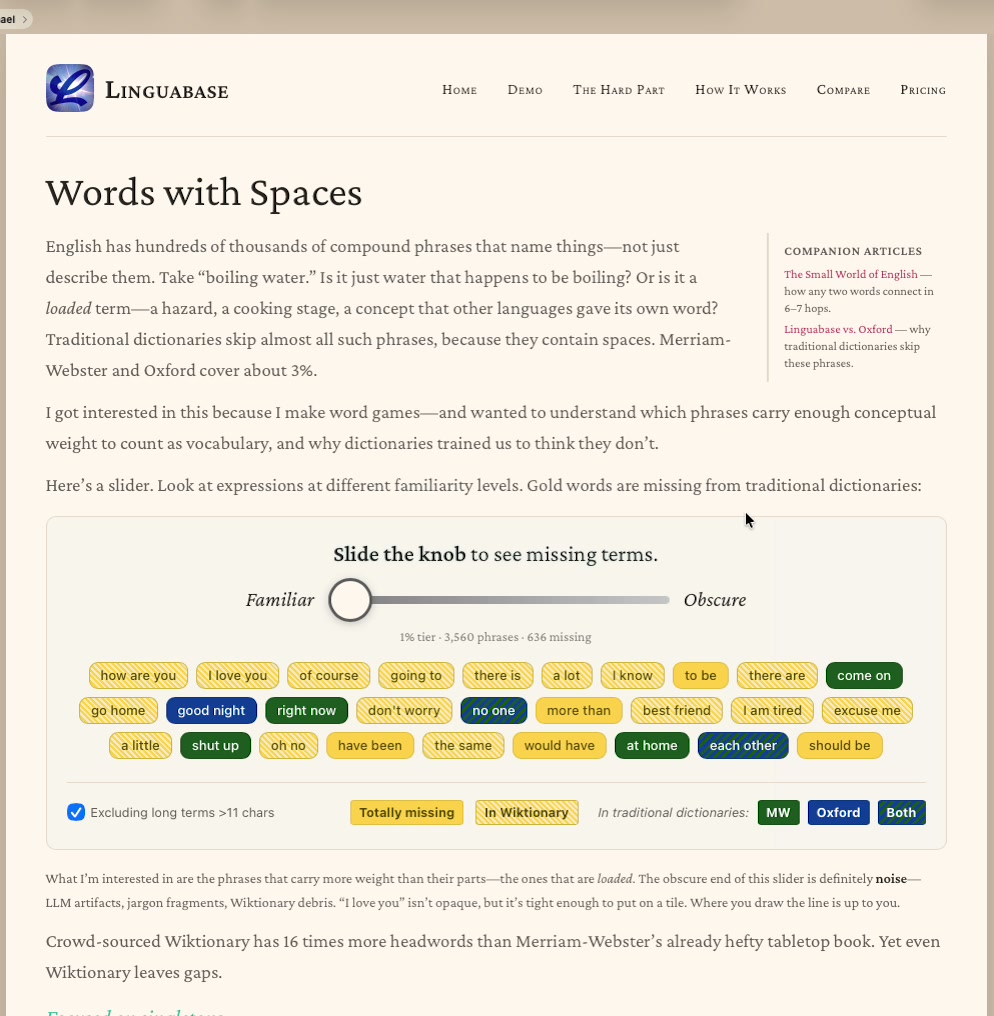
Interactive data visualizations
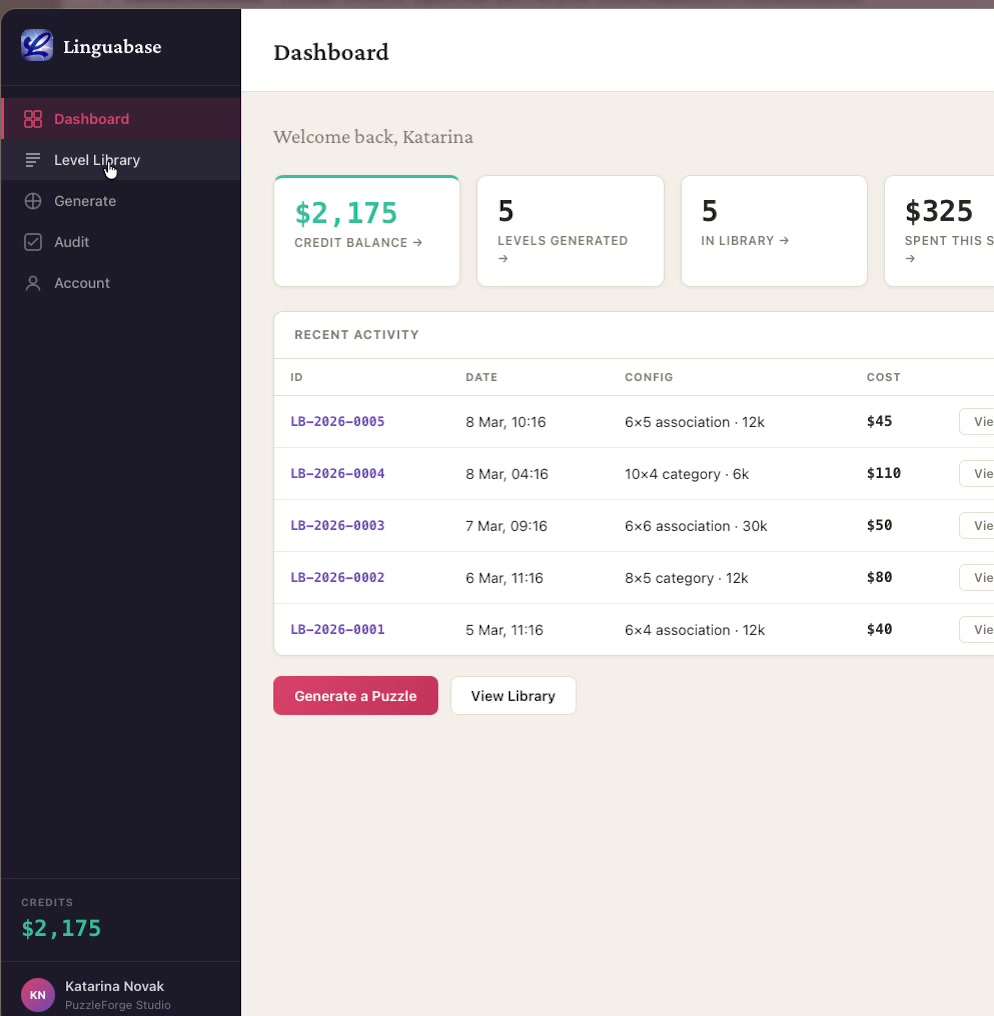
Client portal dashboard
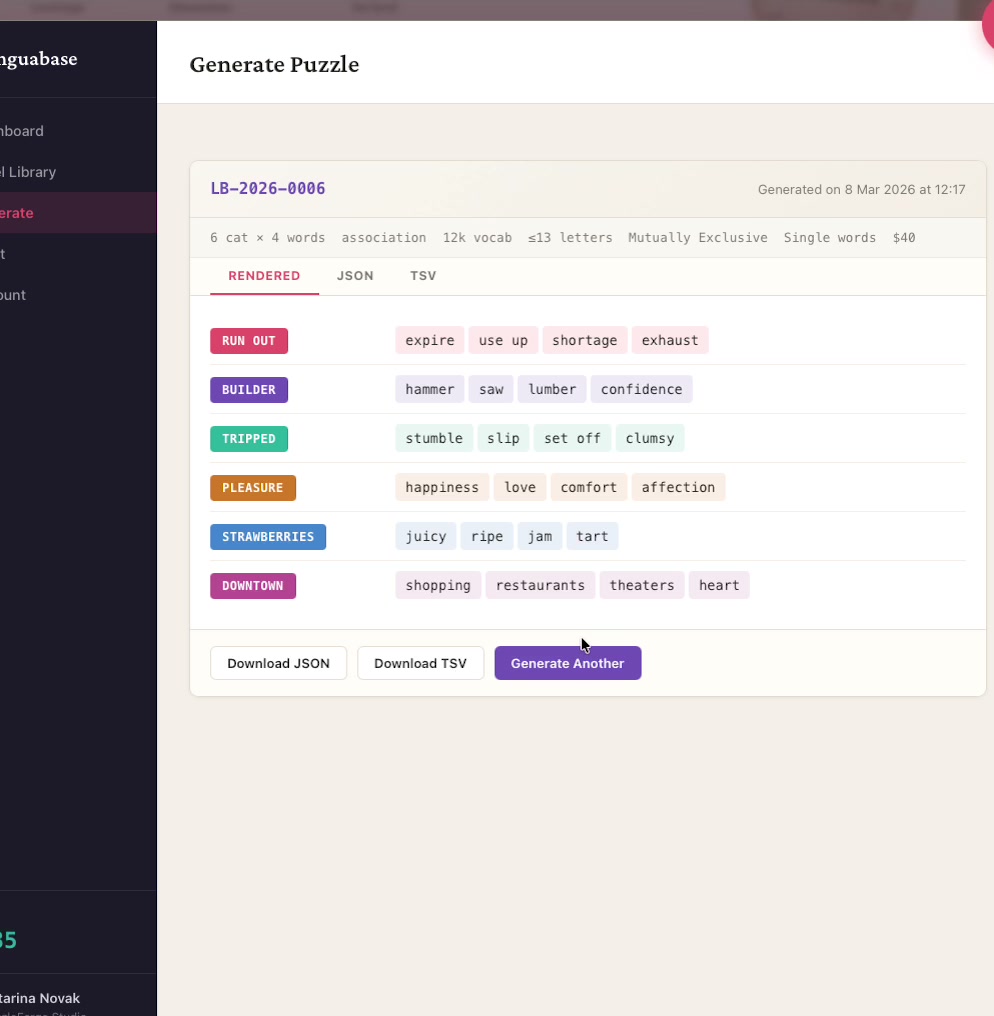
Puzzle generation output
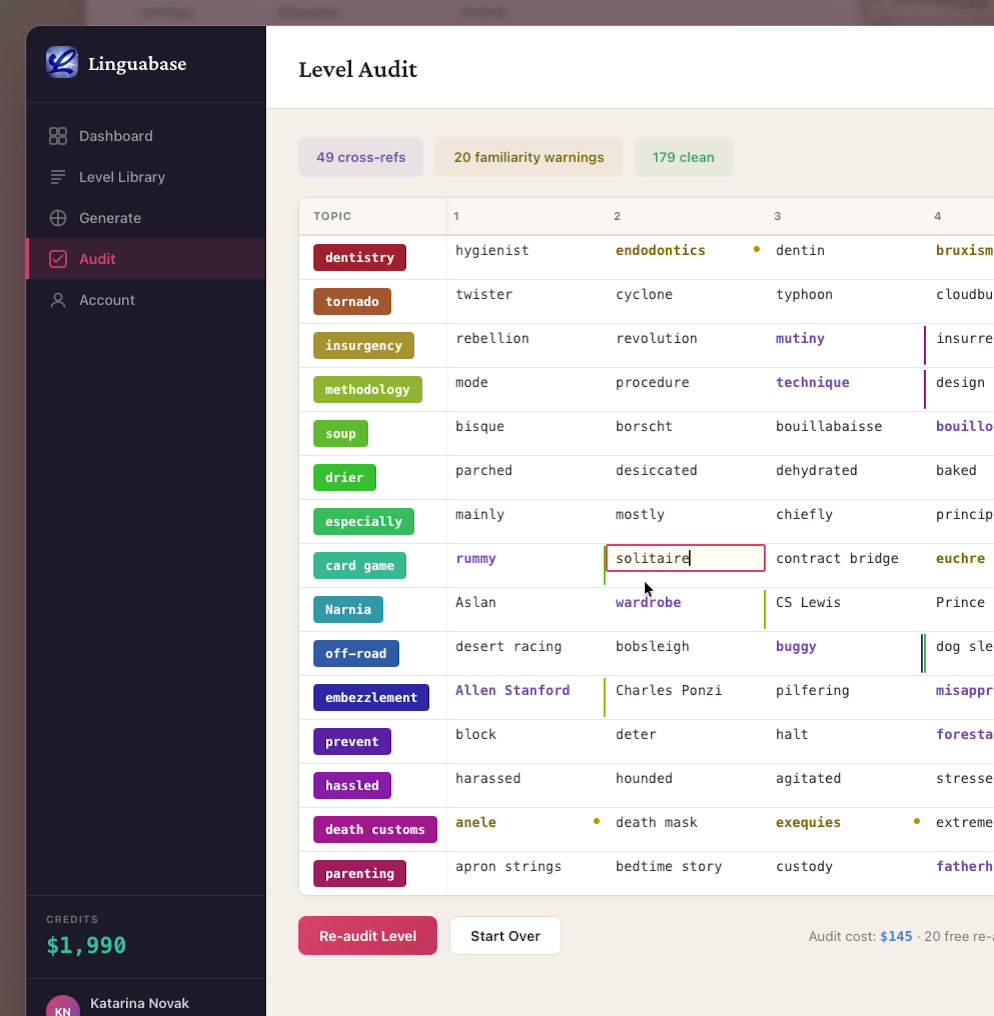
Data audit & quality analysis
linguabase.org — static HTML + CSS + vanilla JS · GA4 · responsive · no frameworks
In the last couple of weeks, as a side project, I had the idea to license out the data to other game studios — because word association games are becoming a thing, like the New York Times Connections game. And it’s amazing — I’ve been in the tech industry a long time. I created a new website with interactive data visualizations, real playable games you can touch and drag, a backend for loading and auditing games — in weeks. Something that would have been a one or two year project just a few years ago. There are types of refreshed presentations for the CIF website, or refreshed access to data that would have been buried — because it would have been unrealistic to tag the video and tag the report and tag the toolkit — that are really possible now. If that’s interesting to you, I’m a great colleague to help you get that online in this new AI era. With that, I’ll close up this presentation and I want to answer your questions.